
前言
众所周知垃圾爬虫(恶意爬虫)对网络安全、网站性能和用户隐私等方面存在多方面的危害,因此网站管理员需通过 User-Agent 检测、IP 限制、多重验证等技术手段,全面防御恶意爬虫的威胁。
本文99开发网将为大家详细介绍 Nginx 服务器如何利用 User-Agent(简称 UA) 规则高效拦截垃圾爬虫。
实现的需求
为常见的主流搜索引擎爬虫设置白名单,避免被误封。
编写常见的垃圾爬虫识别规则,普通用户浏览器不会触发任何规则(默认放行)。
规则文件单独存放,方便后续维护以及多站点复用。
创建规则文件:block_bad_user_agents.conf
# 安全封禁配置 (确保搜索引擎通行)
map $http_user_agent $bad_ua {
default 0;
# 严格限定的搜索引擎白名单
~*(googlebot|bingbot|yandex|duckduckbot|baiduspider|sogou|360spider|exabot|facebot|facebookexternalhit|twitterbot|applebot|petalbot) 0;
# === 恶意爬虫规则 ===
# 扫描器
~*(sqlmap|nmap|nikto|dirbuster|hydra|metasploit|nessus|openvas|zgrab|acunetix|netsparker|havij|appscan|sqlninja|w3af|owasp|brutus|medusa) 1;
# 漏洞特征
~*(eval\(|base64_encode|base64_decode|phpinfo|passthru|shell_exec|system\(|proc_open|popen|curl_exec|curl_multi_exec|show_source|file_put_contents|fwrite|unlink\(|/etc/passwd) 1;
# 恶意爬虫
~*(httrack|harvest|extract|grab|miner|pycurl|masscan|zgrab|binlar|casper|checkpriv|choppy|comodo|diavol|finder|flicky|grabnet) 1;
# 攻击客户端
~*(Go-http-client|Java/1\.|Dalvik/|okhttp/|Apache-HttpClient|python-requests|python-urllib|python-http) 1;
# 其他恶意UA
~*(jbrofuzz|kmccrew|maui|morfeus|netcat|nstealer|planetwork|purefinder|sucker|turnit|vikspider|xxxy) 1;
# 扫描行为
~*(scan|dirbuster|dir\ buster|web\ scanner|vulnerability\ scanner|security\ scanner) 1; }将以上内容保存至 /www/conf/block_bad_user_agents.conf 文件中。
如果在其它路径,需要注意在后续步骤 Nginx 配置中的引用路径。
Nginx 中引入规则文件
找到包含 http 块的 Nginx 配置文件,并添加以下内容(因 Nginx 的 map 指令只能在 http 块中使用):
# 引入垃圾爬虫屏蔽规则文件 include /www/conf/block_bad_user_agents.conf;
如果是宝塔面板,可参考以下设置方法(软件商店 > Nginx > 设置 > 配置修改):
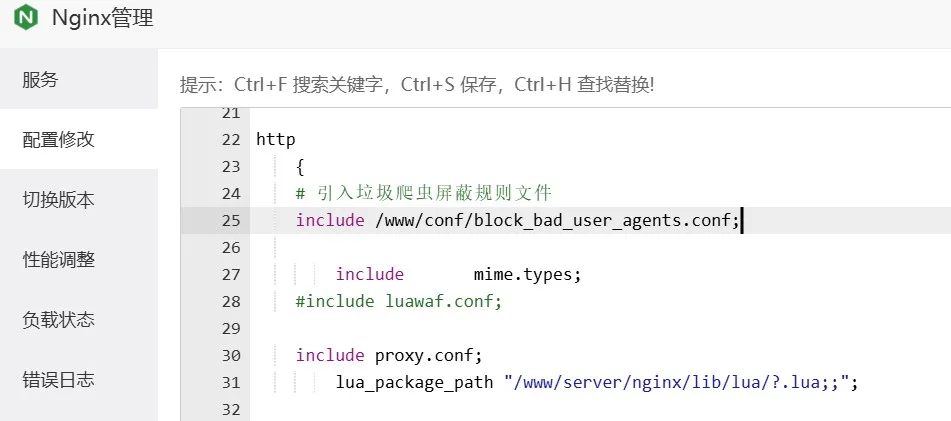
在需要启用拦截的站点配置中添加拦截指令
在需要应用拦截垃圾爬虫规则的站点配置文件的 server 块中添加以下内容:
# 拦截恶意 UA,确保在 http 块中已引入了规则文件block_bad_user_agents.conf
if ($bad_ua) {
return 403;
}宝塔面板,可将以上内容添加到站点设置的伪静态规则顶部,参考以下示例:
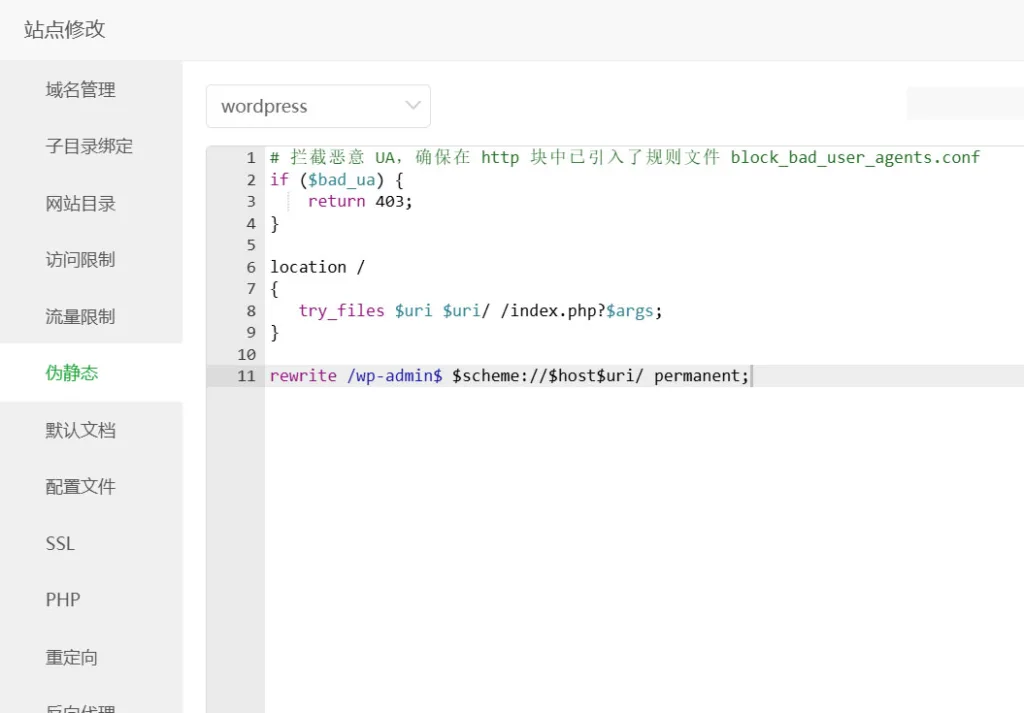
最后重新加载配置文件(不需要重启 Nginx ):
sudo systemctl reload nginx
其它说明
必须确定 block_bad_user_agents.conf 文件的路径与引入垃圾爬虫屏蔽规则文件时所使用的路径一致,否则 Nginx 重载配置会报错。
如果在多站点中复用该屏蔽规则,仅需要在相应站点配置文件的 server 块中添加拦截指令即可。
后续如要更新维护规则仅需编辑 block_bad_user_agents.conf 文件的内容,编辑后需让 Nginx 重新加载配置文件即可生效。
本教程中所列的爬虫验证规则来源于站长帮技术运维团队的经验积累,为大量运维客户实施过,已得到验证。不过为了确保万无一失,建议使用以下指令进行测试。
# 应放行 (返回200) curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://yourdomain.com curl -A "Googlebot/2.1 (+http://www.googlebot.com/bot.html)" https://yourdomain.com curl -A "Baiduspider/2.0 (+http://www.baidu.com/search/spider.html)" https://yourdomain.com # 应拦截 (返回403) curl -A "sqlmap/1.7.5" https://yourdomain.com curl -A "Mozilla/5.0 (compatible; masscan/1.0;)" https://yourdomain.com
注意 https://yourdomain.com 应替换成实际的站点域名。
提示:对于 WordPress 站点的安全防护而言,选用来自可信来源的主题和插件,并合理配置 Web 服务器,是构建安全体系的两大核心要素。










